Published on to joshleeb's blog
This doc outlines the design of the Kar program, a precursor to Pinto. The purpose of Kar is to be a testbed for developing the core idea of Pinto and exploring technical approaches for critical components such as search.
Pinto is a system being developed around the the core idea of curating one’s own subgraph of the web. At the time of writing, I am at the early stages of figuring out specifically what this means, and how it will work. For more details see A Garden Analogy of Pinto.
To aid in this process, I will be developing a command line tool called Kar. This program will make is possible to assess the utility of Pinto’s core idea, and to figure out specific details from both a product and technical perspective.
Definitions
- Document: a blogpost, article, or other web page
Goals
The purpose of the Kar program will be achieved through the following goals.
- To install, refresh, and remove documents from the graph with minimal
information explicitly provided
- That is, only requiring the URL be provided, not document titles or other metadata
- To query documents in the graph with support for full-text search of the document content and applying filters to the list of documents
Non-Goals
- To explore or implement an RSS reader
- To provide support for a document reading list
- To use document content for offline viewing
Design Proposal
Kar is a command line tool. It’s API, inspired by Pacman, has the top-level operations that operate on the store of documents:
-S, --syncto synchronize documents, including installing and refreshing;-Q, --queryto query documents, including full-text search; and-R, --removeto remove documents
as well as the standard operations -V, --version and -h, --help to display
version and usage information respectively.
Additional options and arguments are supported, with some depending on the operation selected. This document will not enumerate all options though some are mentioned in the relevant sections below.
Data stored and accessed as part of these operations is persisted to
disk in the statedir directory, configured with the --statedir option.
Following the XDG Base Directory Specification, the default state
directory will be ${XDG_STATE_HOME}/kar/. More details on storage will be
covered in the relevant sections below.
Sync Operation
Synchronizes documents in the graph. kar -S [OPTIONS...] <URLS...>
New documents are installed by downloading the document’s content, and
updating the database and search index. For example, kar -S https://example.com.
Documents already stored are refreshed which ensures the content on disk is
up to date which is mostly important for updating the search index. For
example, kar -Sy will check all documents and refresh those with content
changes, and kar -Syy will refresh all documents regardless of whether
updates have been detected.
Installing Documents
Before installing a document, the URL is validated in accordance with the URL Standard which is implemented by the url crate. However, this standard does not impose limits for the length of the URL. For this, Kar limits URLs to 8KB as recommended by RFC 9110 §4.1.
Additional validations will also be checked, and normalizations will be applied to the URL. These normalizations are assumed not to change the resource being located.
- Apply RFC 3986 normalization (see Cloudflare docs)
- Lowercase the scheme component, and validate it is
httporhttps - Validate the username and password components are empty
- Validate the host is a domain and not an IP address and lowercase
- Remove the trailing dot from the domain, if present
- Validate an explicit port is not defined (to be inferred from the scheme)
- Normalize the path and path segments
- Replace back slashes with forward slashes
- Merge successive forward slashes
- Apply path segments
./and../ - Strip final slash trailing the full path
- Remove the fragment component, if present
Once validated and normalized, a GET request is issued to the URL to download
the document content. If the content mime type is not text/html the
installation process is aborted and an error is displayed. Otherwise, the
document content is stored at the path content/${uuid} within the state
directory, where ${uuid} is a version 4 UUID.
Note that more content types might be supported in the future. For more details see the Future Work section in the appendix.
Metadata derived from the content and the URL is inserted into the documents
table in the ${statedir}/db.sqlite database which has the following schema.
CREATE TABLE documents (
internal_id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
domain TEXT NOT NULL,
url TEXT NOT NULL UNIQUE,
ext_equiv_url TEXT NOT NULL,
title TEXT,
content_path TEXT NOT NULL UNIQUE,
content_max_age_secs INTEGER NOT NULL,
content_etag TEXT,
content_updated_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
created_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP
);
url is the normalized document URL and domain is the host component parsed
from the URL which includes all subdomains.
ext_equiv_url is the extended equivalence URL, the details of which are
discussed below.
title is the document title scraped from the <title> tag in the document
content. There is no guarantee the content will have a title so this be an
optional value. If no title is present, a value derived from the URL will be
used.
content_path is the path to the document’s content within
${statedir}/content/ and content_updated_at is the timestamp when the
content was last fetched.
content_max_age_secs and content_etag are discussed in the section
Refreshing Documents below.
Handling Redirects
When the GET request is made to the document’s URL, the response might indicate a redirection to the resource.
For status codes 301 MOVED PERMANENTLY, 303 SEE OTHER, 307 TEMPORARY REDIRECT, and 308 PERMANENT REDIRECT: the redirection will be followed iff the URL has the same second-level domain and top-level domain. Otherwise, the response will be treated as a 404 NOT FOUND. For example:
- follow
example.comtobar.example.com; - follow
foo.example.comtoexample.com; - follow
foo.example.comtobar.example.com; - do not follow
example.comtoexample.com.au; and - do not follow
exmaple.comtonot-example.com.
For status code 302 FOUND: content will be fetched from the redirection URL,
but the original URL will be stored in the documents.url field in the
metadata database.
For all other 3xx status codes, or when the above conditions are not met: the response will be treated as a 404 NOT FOUND.
Identifying Duplicates
Identifying duplicate documents is based on the normalized URL, and is done as a best effort. There is no functional requirement to identify duplicates, however a false-positive would be a negative experience for the user.
Installing a document with a URL equivalent to an existing document, where equivalence is defined by §4.6 of the URL Specification, will be prevented as two documents with equivalent URLs are to be considered duplicates. Since URLs in the database are already normalized, this check is trivial.
Installing a document with a non-equivalent URL is allowed, even if the URL points to content that has already been downloaded. The two documents are considered distinct because their normalized URLs are distinct.
However, there are cases where it is likely that two URLs are functionally equivalent (i.e. locate the same resources) even though their normalized forms are different. These cases are the following.
- Equivalence excluding schema
- E.g.
http://example.comandhttps://example.com
- E.g.
- Equivalence excluding common lowest-level domain
- E.g.
http://example.comandhttps://www.example.com
- E.g.
- Equivalence under path case insensitivity
- E.g.
example.com/fooandexample.com/FOO
- E.g.
- Equivalence excluding query parameters
- E.g.
example.com/fooandexample.com/foo?bar=1
- E.g.
To check these cases, for extended equivalency, the ext_equiv_url field will
be populated with the normalized URL modified with the above cases applied as
transformations, e.g. stripping the schema.
Then, installing a document with a URL that has extended equivalence to an existing document will cause the user to be prompted. They will be warned that this new document might be a duplicate and asked whether they wish to proceed with installation.
Rebuilding Metadata
A property that would be nice to have, but is not required for normal
operation, is to be able to rebuild the metadata database (and search index)
from the downloaded content in ${statedir}/content/. Since the metadata is
derived deterministically from the content and the URL this should be
possible.
However, the content is not guaranteed to contain the URL, and the URL cannot be embedded in the content path (even with filepath safe encodings such as base32) due to the limitations imposed on path lengths by many filesystems.
To solve this, Kar maintains an associative list of content path and URL pairs
in the file content/index in the state directory. When content is added or
removed from this directory, the index file is updated accordingly.
Refreshing Documents
On the web, documents might change over time. Although Kar does not support viewing document content offline, having out of date content might have a negative impact on the search quality.
I expect users will have no problem exceeding 1k documents. Naively refreshing the content for even 1/10th of those documents is prohibitively expensive both in time and network cost. To limit this cost, Kar uses a combination of cache headers, entity tags (etags), and timestamps to make conditional GET requests or (better yet) skip making a request entirely.
As part of a successful document installation, the content_updated_at
timestamp is set in the documents table, and the content_etag is set from
the ETag header, if present. Also, content_max_age_secs is set from either
the Expires header or the max-age directive in the Cache-Control header
(the latter being preferred). If neither of these values is present in the
response then a default value is set to 8 hours = 28,800 seconds.
Then, when refreshing a document the process is
- skip if
now < content_updated_at + content_max_age_secs; - otherwise, make a request
GET ${url}- with headers
If-None-Match: ${content_etag}If-Modified-Since: ${content_updated_at}
- skip if the response is 304 NOT MODIFIED
- otherwise, apply the updated content
- with headers
As mentioned above, calling kar -Syy will bypass these checks and all
selected documents will be forcibly refreshed.
Broken Links
Unfortunately it cannot be guaranteed that refreshing a document will not encounter a broken URL.
At this stage there doesn’t appear to be much benefit in keeping documents with broken URLs around as the likelihood the link will be fixed is low. So, when encountering a broken URL, the user will be prompted to remove the document.
Note that this policy does not apply when encountering a redirect on refresh which will follow the redirect process outlined above in the Installing Documents section.
Rate Limiting
Kar expects that it might encounter rate limiting, particularly for a graph with many documents of the same domain. Note that this is also a problem when installing links, but it is more likely to be an issue during content refreshes.
For this initial development, Kar does not have special handling for rate limiting. That is, if rate limited, Kar will early exit from refreshing (or installing) the document and display an error. Of course, this is not ideal but coming up with a better solution will require some more investigation and thought. For now, it is included in the Future Work section in the appendix.
Query Operation
Queries documents in the graph. kar -Q [OPTIONS] [QUERY...]
Querying is centered around the full-text search (FTS) of document content. Additional filters and projections are then be applied to the FTS results.
An empty query will skip FTS and select all documents. Multiple queries will be concatenated together with a space delimiter.
Disclaimer: I have very little knowledge about search systems, and very little experience designing and building them. Further learning and research will be undertaken to improve search functionality and performance, but at this stage simplicity and getting something working is heavily favored.
FTS is implemented by the tantivy crate. The search index is
written to index/ directory. Most of the configuration for indexing,
tokenizing, searching, etc. will use the default parameters defined by the
crate.
Kar supports the following filters:
--url TEXTto filter documents with a url containing${TEXT};--domain TEXTto filter documents with a domain containing${TEXT}; and-n, --limit Nto limit the number of results to${N}(max 100)
and the following projections:
-o, --only-urlto print only the URLs of documents.
Displaying Documents
Query results are printed as static text. That is, they are output to stdout rather than shown in an interactive interface. As far as I know, most terminals do not support hyperlinking text and so the full URL must be displayed.
Figure 1 shows a concept for the default formatting for displaying a list of documents. Each entry includes the title and the domain, with the latter being omitted if there is insufficient space for both on the same line. Next, the URL is displayed in full. The final line of the entry contains metadata such as when the document was added to the graph.
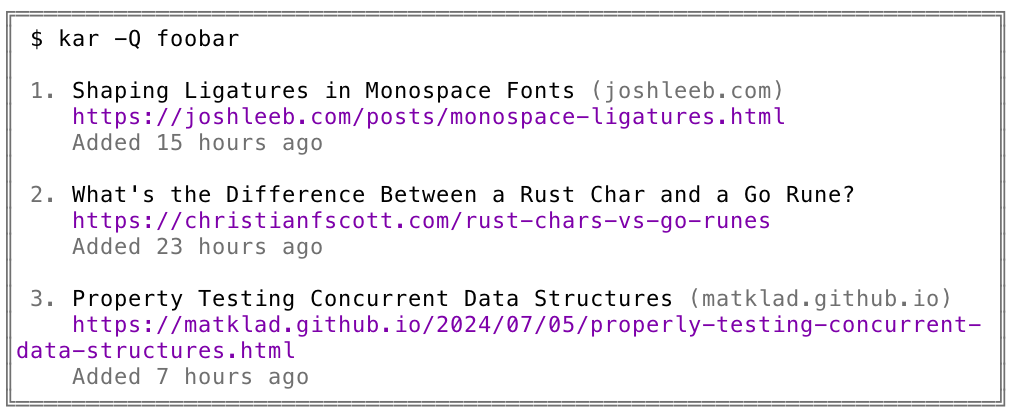
There are many improvements to be made to the way documents are displayed. For more details see the Future Work section in the appendix.
Remove Operation
Removes documents from the graph. kar -R [OPTIONS...] <URLs...>
To remove a document from the graph, multiple locations in the state directory must be updated. These are:
- the
documentstable indb.sqlite; - the
contents/directory andcontents/index; and - the search index at
index/.
Kar only supports hard deletion. Once document content is deleted the document is no longer recoverable.
Appendix
Future Work
Extend Support for Mime Types
Document installation is aborted if the content type is not text/html.
However, there is no reason not to support additional content types such as
text/plain and application/pdf.
Better Handling of Being Rate Limited
The onus to use this tool responsibly is on the user. However, it doesn’t help that refreshing (and installing) documents has the potential to send a high volume of requests to a single domain/server.
Some ideas for how to improve this.
- Introduce a conservative rate limiter applied per domain. Persist the internal state of the limiter at the end of each command so limiting is enforced across executions.
- Explore approaches for automatic rate limiting per domain, e.g. responding to a 429 TOO MANY REQUESTS status code.
Improve Search Architecture
Improve search architecture to increase query performance, in both latency and the quality of results. This will take time as I learn more about search, how it works, different approaches, and the best practices.
Extend Support for Document Display Options
There are many additional filters and projections that can be added to improve how documents are displayed. The default behavior can most likely also be improved along with supporting configuration with environment variables and a config file.
Some ideas for where to improve this.
- Update filters with a text argument (e.g.
--url,--domain) to apply the argument more intuitively, as either a regex, exact match, or fuzzy string search. - Add projections to select sort order, coloring of the output, and turn on or off displaying various bit of metadata.
- Explore options for shortening URLs printed to the terminal, or reconsider having an interactive interface to remove the requirement to display URLs.
- When piping output, only include the URL as though the
--only-urlflag was set and provide an option to output as JSON.
Explore a Browser Extension
Explore the feasibility of a browser extension to install documents with the URL of the active page. This will remove the overhead of copy-pasting the URL into a command in the terminal.