Published on to joshleeb's blog
G’day!
This month I’ve been continuing the momentum with Pinto. The ideas developed from last month on tagging and the design of the Scoped Tagging mechanism (see Scoped Tagging of Bookmarks) have materialized into an implementation. We have scopes, we have tags, and we have pages and a UI to display them both.
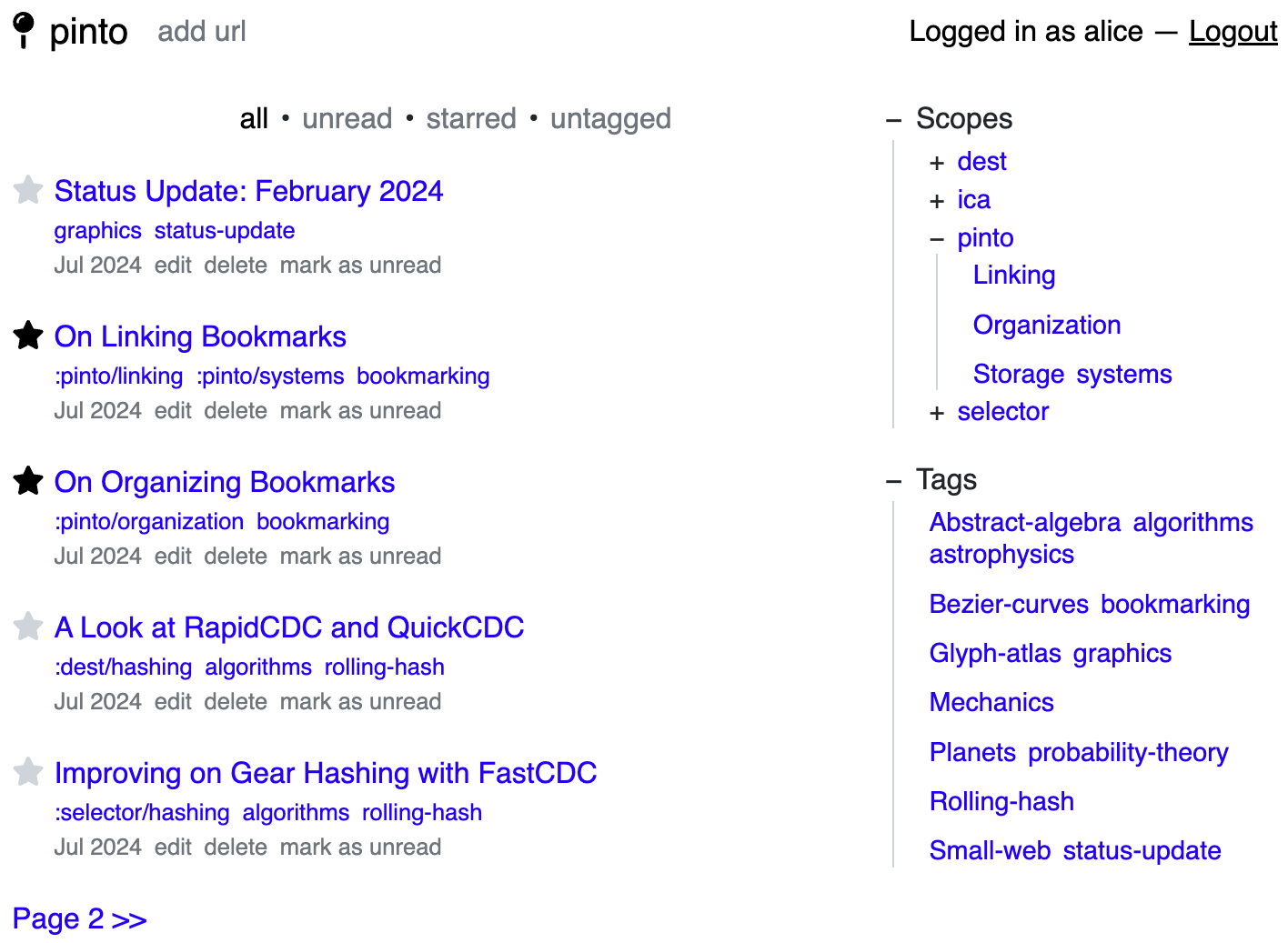
There are a few small tasks remaining to completely wrap up Scoped Tagging, such as adding forms to manually add and edit scopes, but there isn’t a strong need for these right now. So I’m excited to get started on the final piece needed to use Pinto on a daily basis, which has to do with storage.
Pinto uses Postgres for its primary storage. As is common for local development these days we spin up an instance of the database in a Docker container that the server connects to. Once everything is up and running we can then pepper the server with a bank of requests to provide some fake data to work with.
This works great in that it’s easy to teardown the database, change the schema, and repopulate the fake data. Having the database be ephemeral in this way is very convenient for local development.
The problem is, when I’m using Pinto with my personal bookmarks, this ephemerality is undesirable. I need to make sure my bookmarks are stored somewhere else such that they
- won’t be lost when the database is torn down; and
- can be restored to a new instance of the database.
We could setup a separate, more permanent Postgres instance to use for my personal bookmarks but that comes with its own set of issues.
Instead, we’ll implement a mechanism for automatically exporting bookmarks. Then we’ll leverage the system that populates the database with fake data to also repopulate my real bookmarks.
More specifically, whenever a bookmark is created, deleted, or modified, the server will (out-of-band) export all of my bookmarks to a JSON file on disk. The tool that populates the database with fake bookmarks already reads that data from a JSON file so it should be trivial to repopulate the database with my bookmarks as well.
That will be the focus for this month, after which I might take a small break from developing Pinto to actually use what I’ve built and spend time on some other personal projects.
That’s all for now, see you next month!